Нейросеть для SEO-копирайтинга: как не получить фильтр в 2026
Как создавать SEO-тексты с помощью нейросетей и обходить фильтр МПК в 2026 году. Обзор лучших моделей (Claude, Qwen), правила промптинга и SERP-анализа.
- 1 За что поисковики накладывают фильтры на ИИ-тексты
- 2 Как решать задачи SEO-оптимизации без риска пессимизации
- 3 Топ нейросетей для SEO-копирайтинга: что выбрать
- 4 Как написать безопасный SEO-текст: пошаговый алгоритм
- 5 Что делать, если текст получается водянистым
- 6 Кейс: вывод категорийных страниц из-под фильтра МПК
- 7 Частые вопросы
- Соберите структуру через SERP-анализатор
- Выгрузите LSI-фразы конкурентов
- Используйте Claude или Qwen с запретом на вводные слова
- Разбейте текст на абзацы разной длины
По итогам 2025/2026 года доля AI-контента в топ-20 поисковой выдачи достигла 17,31% (источник: Originality.ai, 2025). Любая нейросеть для seo способна выдать читаемый материал за секунды, но без предварительной подготовки такой контент становится токсичным для сайта. Поисковые системы научились безошибочно определять машинный слог, лишенный фактуры и семантического облака. Чтобы алгоритмы Яндекса и Google ранжировали сгенерированные страницы наравне с авторскими, необходимо сменить подход: отказаться от слепых промптов и выстроить процесс на базе жесткого парсинга выдачи.
За что поисковики накладывают фильтры на ИИ-тексты
Алгоритмы Яндекса и Google не ищут водяные знаки нейросетей — они реагируют на математическую предсказуемость текста и бедность словаря. Поэтому делайте ставку на рваный ритм и плотную семантику. Детекторы работают на основе двух ключевых метрик: перплексии и burstiness. Перплексити (perplexity) — нейросеть оценивает, насколько легко языковая модель может угадать следующее слово в предложении. У человека этот показатель всегда высокий, так как живой автор использует неожиданные синонимы, профессиональный сленг и сложные конструкции. Машина же выбирает наиболее вероятные, статистически усредненные слова.
Второй триггер — burstiness (всплески). Это дисперсия длины предложений. Живой автор чередует короткие рубленые фразы из трех слов с длинными сложноподчиненными конструкциями. Базовый ИИ выдает монотонный текст, где каждое предложение состоит из 12–15 слов. Именно эта «гребенка» мгновенно считывается алгоритмами Яндекса как спам.
Официальная позиция поисковиков предельно ясна: они наказывают не за сам инструмент, а за отсутствие добавленной ценности. В 2025 году мы убрали из поиска 45% низкокачественного и неоригинального контента (источник: Google, 2025). Главным маркером такого контента выступает отсутствие LSI (латентно-семантического индекса) — специфических терминов, которые обязательно присутствуют в текстах экспертов. Если статья про ремонт АКПП не содержит слов «гидроблок», «соленоид» и «фрикционы», она получает статус малополезной. Чтобы обойти этот барьер, насыщайте промпты терминологией до старта генерации.

Как решать задачи SEO-оптимизации без риска пессимизации
Разделите процесс на этапы: сбор данных доверьте специализированным парсерам, а нейросети отдайте только финальную сборку текста по жестким правилам. Масштабирование контента через единую кнопку «написать статью» больше не работает. Оптимальный пайплайн требует разделения ролей между инструментами автоматизации SEO и текстовыми моделями.
Для создания структуры парсите заголовки конкурентов из топ-10. Если вы продвигаете клинику, алгоритм должен собрать все обязательные блоки из выдачи: цены, квалификацию врачей, противопоказания, этапы процедуры. Этот каркас передается ИИ как неизменяемое ядро. Нейросети для seo отлично справляются со связыванием готовых фактов, но они не умеют придумывать релевантную структуру из пустоты.
Оптимизацию мета-тегов также поручайте нейросети строго по формуле. Title и Description не должны быть креативными — они обязаны содержать точное вхождение ключа и коммерческие триггеры. Задайте модели шаблон: «[Главный ключ] — [Преимущество] | [Название компании]». Нейросеть продвижение seo ускоряет в разы, если ограничить ее фантазию рамками технического задания. Сначала соберите кластеры запросов, назначьте им посадочные страницы, и только затем запускайте пакетную генерацию по заранее утвержденным шаблонам.
Топ нейросетей для SEO-копирайтинга: что выбрать
Выбирайте модель в зависимости от задачи: для сложных экспертных статей берите Claude, для массовых описаний товаров — Qwen или GigaChat. Рынок AI-инструментов сегментировался, и универсального решения больше нет. Цены на API-доступ к моделям в 2026 году варьируются от $0.5 до $15 за 1 млн токенов (источник: Прайс-листы провайдеров, 2026). Ниже приведено сравнение актуальных решений для вебмастеров.
| Модель | Специфика применения | Качество русского языка |
|---|---|---|
| Claude 3.5 Sonnet | Информационные статьи, лонгриды, блог | Идеально. Минимум штампов, отлично держит структуру и стиль. |
| Qwen Max | Серые ниши, коммерция, массовая генерация | Отлично. Qwen нейросеть не имеет жесткой цензуры на коммерческие тематики. |
| ChatGPT-4o | Универсальные задачи, перевод, код | Хорошо, но требует жестких промптов для подавления «ИИ-акцента». |
| GigaChat | E-com карточки, рерайт новостей | Базовое. Подходит для простых описаний без глубокой экспертизы. |
Любой агрегатор нейросетей позволяет тестировать эти модели в одном окне. Seo ai нейросеть должна оцениваться не по умению писать красивые метафоры, а по способности строго следовать техническому заданию и вписывать ключевые слова без потери смысла. Если модель начинает игнорировать лимиты символов или теряет LSI-фразы на середине текста — меняйте провайдера.
Как написать безопасный SEO-текст: пошаговый алгоритм
Откройте инструмент генерации статей SeoFab, введите якорный запрос и позвольте алгоритму собрать структуру на основе реальной выдачи до того, как начнется генерация. Безопасная нейросеть seo тексты создает только на фундаменте данных. Следуйте этому алгоритму, чтобы написать seo текст нейросеть не смогла отличить от экспертного материала.
Шаг 1: Сбор структуры через SERP-анализатор
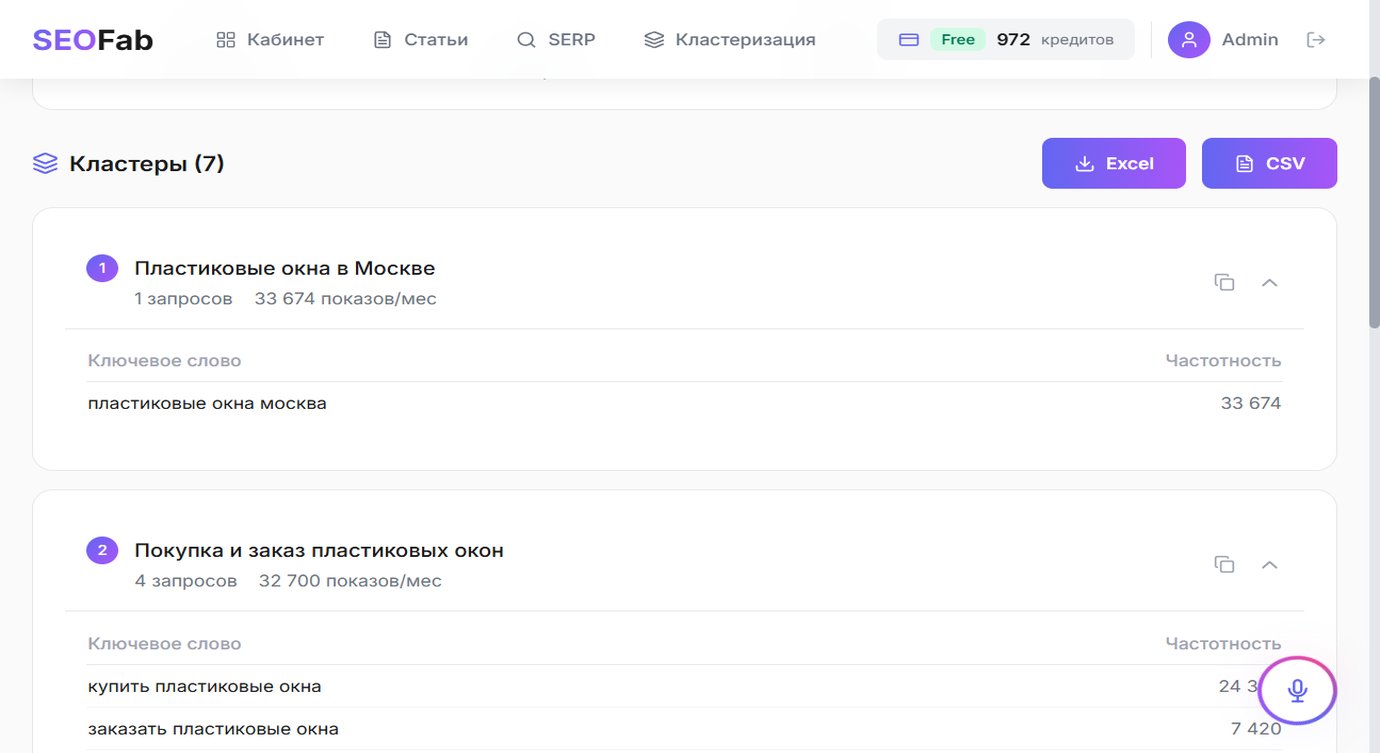
Загрузите целевой запрос в систему для выгрузки структуры топа. Алгоритм проанализирует первые 10-20 сайтов в Яндексе или Google и покажет, какие H2 и H3 используют конкуренты. Выберите наиболее полные блоки и объедините их в единый план. Это гарантирует, что статья полностью раскроет интент пользователя.
Шаг 2: Выгрузка LSI-ядра и коммерческих маркеров
Скопируйте список обязательных LSI-фраз и сущностей. Если вы пишете про монтаж кондиционеров, система с помощью встроенного генератора статей на базе SERP подсветит слова: «штробление», «трасса», «фреон», «вакуумирование». Без этих слов поисковик сочтет текст поверхностным. Включите их в обязательное задание для ИИ.
Шаг 3: Настройка системного промпта
Укажите роль, запрет на стоп-слова и требуемый ритм предложений. Типичный рабочий промпт выглядит так: «Действуй как Senior SEO-специалист. Напиши текст для раздела H2. Запрещено использовать слова: безусловно, однако, кроме того,. Чередуй предложения из 5 слов с длинными конструкциями до 20 слов. Используй маркированные списки». Это ломает машинный паттерн.
Шаг 4: Поблочная генерация контента
Сгенерируйте текст поблочно (по одному H2 за раз), контролируя вхождения ключей. Не просите модель написать сразу 10 000 символов — у нее ограничен размер контекстного окна внимания. Отдавая по одному подзаголовку, вы контролируете плотность ключевых слов и сохраняете фокус на теме раздела.
Шаг 5: Ручная вычитка (Human Touch)
Проведите ручную вычитку и удалите оставшиеся штампы. Проверьте факты: цены, названия брендов, технические характеристики. Нейросети склонны к галлюцинациям, поэтому финальный контроль всегда остается за редактором. Добавьте в текст пару честных оговорок из практики — например, «здесь часто промахиваются на выборе мощности сплит-системы». Это резкий маркер живого автора.
Что делать, если текст получается водянистым
Если антиплагиат или детектор ИИ показывает высокий процент машинного текста, не пытайтесь синонимизировать слова. Измените структуру предложений и добавьте фактуру. Текстовая нейросеть всегда стремится к обобщениям, если ей не дать конкретных вводных. Исправить ситуацию можно тремя точечными корректировками промпта.
Первая проблема: текст начинается с шаблонных фраз. Если абзац стартует с «...», «Ни для кого не секрет...» или «Сегодня каждый бизнесмен...» — это мгновенный сигнал для фильтра МПК. Добавьте в системный промпт жесткий запрет на вводные конструкции. Заставьте модель начинать абзац сразу с действия или цифры. Турботекст нейросеть или аналогичные сервисы часто выдают такие клише по умолчанию, поэтому их нужно подавлять на уровне базовых настроек.
Вторая проблема: одинаковая длина абзацев и предложений. Это та самая burstiness, о которой говорилось выше. Принудительно задайте правило в задании: «чередовать короткие предложения (3-5 слов) с длинными». Попросите ИИ использовать парцелляцию. Разбейте сплошную стену текста с помощью списков, таблиц и врезок. Использование анализатора топа выдачи для сбора LSI поможет разбавить воду плотными терминами.
Третья проблема: низкая уникальность или статус «Сгенерировано ИИ» по Text.ru. Не используйте синонимайзеры — они ломают смысл и читабельность. Перепишите секцию, добавив конкретные цифры и факты из вашей ниши. Вместо «наши специалисты имеют большой опыт» задайте модели факт: «в штате 5 инженеров с допусками по электробезопасности 4 группы». Конкретика немедленно снижает процент машинного текста в анализаторах.
Кейс: вывод категорийных страниц из-под фильтра МПК
Для снятия фильтра «Малополезный контент» полностью удалите сгенерированный без LSI текст и замените его на плотную, структурированную выжимку. Полумеры здесь не работают: если страница уже пессимизирована, косметические правки пары абзацев не заставят алгоритм переиндексировать документ с положительным вердиктом.
Исходные данные: крупный региональный интернет-магазин сантехники потерял 40% органического трафика из Яндекса. Причина — массовая генерация 800 описаний категорий через базовый ChatGPT-3.5 без предварительного парсинга. Seo описание нейросеть выдала водянистое: «Наш магазин предлагает широкий ассортимент ванн, которые украсят ваш интерьер». Никаких LSI-слов вроде «акриловые», «чугунные», «экран», «слив-перелив» в текстах не было. Страницы улетели за топ-50.
Действия: команда полностью снесла старые тексты. Был проведен сбор LSI через SERP-анализ для каждой категории. Далее настроили перегенерацию через Qwen с жестким лимитом на 1500 символов и 100% вхождением коммерческих маркеров («купить», «цена», «в наличии», «доставка»). Промпт запрещал любые прилагательные-оценки («красивый», «надежный») и требовал оперировать только свойствами из карточек товаров (толщина акрила, тип установки).
Результат: снятие фильтра произошло через 3 недели после отправки страниц на переобход. Возврат позиций в топ-10 Яндекса зафиксирован по 75% обновленных категорий. Трафик восстановился и превысил исторический максимум на 12%. Этот случай доказывает: поисковики не банят за ИИ, они банят за лень и отсутствие фактуры.
Частые вопросы
Ознакомьтесь с ответами на самые частые вопросы по использованию ИИ в SEO-продвижении. Seo оптимизация под нейросети требует четкого понимания правил игры.

Разработал сервис с инструментами для повышения эффективности маркетинга и его автоматизации. Кроме этого — практикующий SEO-специалист: аудиты, семантика и продвижение коммерческих сайтов. Пишу о маркетинге, ИИ в бизнес-процессах и автоматизации.
- Originality.ai, 2025 — доля AI-контента в поисковой выдаче.
- Google, 2025 — данные по удалению низкокачественного контента.
- Прайс-листы провайдеров, 2026 — цены на API-доступ к моделям.
Нейросеть для seo — это только печатная машинка; структуру и фактуру для неё должен собирать алгоритм анализа выдачи. Прекратите генерировать тексты вслепую и рисковать трафиком из-за фильтра МПК. Начните выстраивать конвейер правильно: соберите LSI-ядро, проанализируйте конкурентов и попробуйте генератор статей SeoFab для безопасного масштабирования контента.